



评价一款游戏的性能好坏,我们通常会用到帧率(每秒钟的渲染帧数)作为主要参考指标。当然,手游这块功耗也是一个重要因素,但主要还是看帧率。像MOBA、FPS类的游戏,帧率肯定是越高越好,出于功耗与显示设备的限制,一般跑满也就在60fps左右。而像其他的棋牌、放置类游戏,帧率只要有30fps就足够了。
性能优化要谨遵二八原则:20%的代码影响80%的性能瓶颈。因此要合理地找出性能瓶颈所在,避免负优化。下面就三个比较常见的方面:bandwidth、drawcall、overdraw 来分别阐述渲染阶段是如何造成性能瓶颈以及对应的解决办法。
移动端的GPU设计之初,优先注重的肯定是功耗问题,然而在实际渲染一帧图像的时候,对功耗影响最大的因素就是带宽(bandwidth)。
为什么会是带宽呢?
这是因为出于空间的考虑,手机芯片的设计上采用了SoC架构,因此内存与显存实际上是共享在一块物理内存上的,在OpenGL ES规范中,内存与显存中的数据却不能共享。在有限带宽的前提下,我们不妨计算一下,一台分辨率为1920*1080的移动设备,按60帧率来算,每秒钟1次overdraw产生的数据量为:
1920 * 1080 * 32 * 60 / (1024 * 1024)=3.7 Gb
如果遇到了大量的半透明物体或是粒子特效,那么数据量上可能会成倍的增长。
如此大量的数据存储在显存的FrameBuffer中,GPU要以高昂地代价频繁地去显存访问FrameBuffer里的数据,这显然是很难接受的。因此在移动端的显卡硬件上,想到了一种优化方式,就是将FrameBuffer拆分成不同的小块(tile),每次可以先将这一小块的数据放到访问速度更快的On-Chip Memory中去,GPU会先从tile中一块块地去进行渲染,等整体渲染完成之后,再将数据搬回显存上。
我们将这种模式称为 TBR(Tile Base Rendering)。
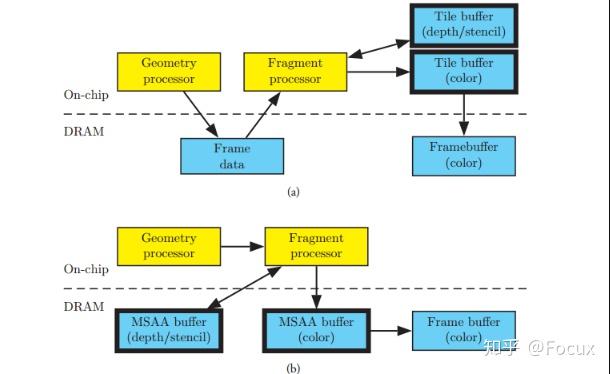
然而在TBR模式下,可能存在着这样的一个问题,如果对于CPU每一次传来的绘制命令都进行渲染的话,那么GPU必定会频繁、大量地对tile数据进行搬迁操作,这显然是不可接受的。为了解决这个问题,TBR一般的策略是:对于CPU提交的Draw Call请求,先只做顶点处理,将Vertex Shader计算的结果暂存到一个叫 FrameData 的地方。等到执行 Swap Buffer 的时候,再对整个数据做光栅化,进行绘制。
既然是等所有的FrameData数据处理好后一次性进行绘制,GPU硬件上便进一步做了些延迟渲染相关的优化。例如iOS上的PowerVR,专门有一个叫 ISR 的硬件,会去处理FrameData中那些诸如深度测试、模板测试没有通过的数据,尽可能地只去渲染那些最终影响FrameBuffer的物体。
我们将这种模式称为 TBDR(Tile Base Deffered Rendering)。
基于移动端GPU特有的架构模式,需要我们做哪些优化方面的事情或是注意事项呢?
- 使用压缩的纹理格式,如ETC、PVR等
- 打开Mipmap(内存与带宽的权衡)
- 减少Shader中的采样次数,尽量合并一些通道图
- 控制总顶点数量
- 不要频繁地切换FrameBuffer(后处理效果)
手机上CPU与GPU的关系,就好像客户端与服务端的CS架构。所谓Drawcall,可以理解为Client端的CPU向Server端的GPU发送的一次绘制命令,同时会传递需要被渲染的图元列表。现代GPU就为了高并发处理数据而生的,一般Drawcall的绘制数据计算起来应该还是绰绰有余。但由于CPU传递的渲染数据得通过PCI-E总线才能传到GPU显存中的全局存储区域,频繁且大量地提交绘制相对简单的绘制命令,会造成GPU端的“ 产能过剩 ”,CPU无法及时提供渲染数据而造成性能瓶颈。
与此同时,TBR架构下优化过的GPU,会先将顶点数据存储到FrameData队列,如果Drawcall数量过多,且顶点数量巨大,万一FrameData承装的内存放不下了,就得先将数据移动到别处,进而大大降低了访问速度。这也是我们需要控制DrawCall数量和顶点数的一个重要原因。
游戏开发中,常见的降低Drawcall的方式,无非以下几种:
在每一帧都对需要的网格进行合批处理,这样的好处就是合批的物体仍然可以各自移动,但是必须使用同一个材质。当所需合批的顶点数过多时,其实会对CPU产生额外的计算开销。因此在做动态合批的时候,通常会有顶点数的限制,需要根据实际需要做好取舍。
只进行一次合批处理,生成一个大的网格,性能优于动态合批,但没有动态合批灵活(只能作用于静态物体),并且会有较高的内存占用。
根据机型或摄像机距离,使用不同的材质shader,尽可能地降低细节表现,去除不必要的渲染Pass以及计算开销。
常见于大世界场景的游戏中,对于摄像机可视范围之外的物体可以进行视锥体剔除,但是可视范围内的那些已经被遮挡住了的物体,可能仍然会去进行绘制,造成不必要的性能损耗。
对需要绘制的物体进行排序,是游戏引擎规避性能开销的一种常见手段。非透明物体相对摄像机由近及远地排序绘制,可以有效剔除那些深度测试不通过的片元。但对于那些未被遮挡(深度测试通过)的透明物体,由于需要开启混合计算,因此在Early-Z阶段也没法剔除掉那些背后的图元数据,这就造成了同一个像素的多次(过度)绘制,即我们常说的 Overdraw 。
GPU中跟Overdraw有关的指标可以参考像素填充率,即每秒所能渲染的最大像素数量。在确保带宽没有遇到性能瓶颈后(改用压缩纹理格式),如果降低设备分辨率后,帧率一下子上去了,那么很可能就是像素填充率遇到了瓶颈。这时候就需要看看Overdraw是否在一个合理的范围内,是否有优化的空间。
实际的游戏开发中,最常见的Overdraw大户莫过于粒子特效了。美术同学在制作粒子特效的时候,往往会为了追求细节效果而忽略掉Overdraw的问题。大量的透明粒子相叠加,造成的性能开销是十分可怖的。为此,我们最好在立项之初就设定好一些粒子特效的制作规范,或是一些建议要求来约束美术设计粒子效果。
- 一个复合粒子系统(如爆炸),子特效尽量不要超过5个(叠加过曝也应考虑优化)
- 粒子所占的屏幕面积尽量不要过大,可以考虑使用Mesh来替换
- 纹理中透明不可见的部分尽可能地少
为了照顾低端机型,我们可以对粒子特效采取分级的策略,等级越低,特效表现越简单,同时也可以从粒子数量、运算模块来进行精简。如果还是不能满足性能要求,也可以考虑改用帧动画来替代粒子特效。


