



源自:软件学报
作者:云岳 代欢 张育培 尚学群 李战怀
近年来, 伴随着现代信息技术的迅猛发展, 以人工智能为代表的新兴技术在教育领域得到了广泛应用, 引发了学习理念和方式的深刻变革. 在这种大背景下, 在线学习超越了时空的限制, 为学习者“随时随地”学习提供了更多的可能性, 从而得到了蓬勃发展. 然而, 在线学习中师生时间、空间分离的特征, 导致教师无法及时掌握学生的学习状态, 一定程度上制约了在线学习中教学质量的提升. 面对多元化的学习需求及海量学习资源, 如何迅速完成学习目标、降低学习成本、合理分配学习资源等问题成为限制个人和时代发展的重大问题. 然而, 传统的“一刀切”的教育模式已经不能满足人们获取知识的需求了, 需要一个更高效、更科学的个性化教育模式, 以帮助学习者以最小的学习成本最大限度地完成学习目标. 基于以上背景, 如何自动高效识别学习者特征, 高效地组织和分配学习资源, 为每一位学习者规划个性化路径, 成为面向个体的精准化教育资源匹配机制研究中亟待解决的问题. 系统地综述并分析了当前个性化学习路径推荐的研究现状, 并从多学科领域的角度分析了对于同一问题的不同研究思路, 同时也归纳总结了当前研究中最为主流的核心推荐算法. 最后, 强调当前研究存在的主要不足之处.
人工智能 个性化学习 学习路径 在线学习 资源规划
2012年3月13日, 中国教育部印发《教育信息化十年发展规划(2011–2020年)》, 该规划从宏观上说明了教育信息化的重要性以及具体部署, 并提到要充分发挥政府、学校和社会的作用, 面向全社会不同群体的学习需求建设便捷灵活和个性化的学习环境, 终身学习和学习型社会的信息化支撑服务体系基本形成. 2018年, 教育部再次印发《教育信息化2.0行动计划》, 愈加强调了在如今“大众创业、万众创新”的时代背景下, 个性化学习的重要性.
然而, 尽管人们对于学习资源的获取途径更加多种多样, 在线教育系统的迅猛发展也使得人们对于学习资源的获取更加便捷, 但是伴随着信息时代知识与学习资源的爆炸性增长, 人们获取新知的路上存在若干痛点: 1)新领域的准入门槛增加了学习者获取资源的难度; 2)海量繁杂的学习资源使得人们难以准确获得适合自身需求的学习资源; 3)大量冗余、质量低下甚至错误的学习资源进一步增加了学习者达成学习目标的难度. 为解决当前人们获取新知的若干痛点, 国内外大量的学者针对上述问题展开研究, 并努力提出不同的解决方案[1, 2]. 2019年末, 伴随着新型冠状病毒COVID-19在世界范围的爆发, 以MOOC (massive open online course)平台为代表的在线教育系统迅猛发展, 为学习者提供了更加便捷、高效的学习平台, 一定程度上解决了上述问题. 但是, 传统在线教育系统大多依旧采用一对多的资源分配模式, 忽略了学习者知识背景的不同、学习能力的差异及学习目标的多样性, 依旧未能很好地解决学习者获取新知的痛点. 因此, 在当前的相关研究中, “如何解决学习者的个性化需求”成为完成个性化教学任务的重中之重!
在本课题的研究中, 个性化学习路径推荐指的是, 综合考虑目标学习者的学习能力、知识背景、学习目标等的差异性, 为学习者量身定制一条符合教育学规律且能达到学习者学习目标的学习路径, 并可以实时检测学习者的学习状态[3]. 尽管有很多研究者针对该问题进行了不同层面的研究[1-5], 并取得了一定成果, 但对于相关研究的综述却很不足: 国内学者张蓉等人在综述[2]中, 按照文献发表时间、研究主题的不同对于国内的研究进行了简单研究总结, 但该综述并没有深入具体推荐技术进行剖析, 偏向于政策性研究; 国外学者Nabizadeh等人[4]对于160篇外文文献进行较为全面的综述, 但该项研究仅针对个性化学习路径推荐中的关键步骤, 从教育学学科的角度针对个性化学习路径推荐进行分析. 基于以上考虑, 本篇文章旨在为读者提供多方面、多层次、多角度、全面系统的分析与总结, 方便相关读者迅速进入该领域的研究.
我们利用中国知网学术搜索引擎、Web of Science 平台、Ei Compendex数据库、谷歌学术搜索引擎等, 限定文献发表时间为“2011年1月–2021年4月”, 并分别在外文搜索平台以“learning path”“education adaptive learning system”“personalized adaptive learning”“intelligent tutoring system”“courses generation”“curriculum learning”“course planning”“personalized learning”等为关键词、在中文文献搜索平台以“学习路径”“智能教学系统”“课程规划”“学习序列”等为关键词进行搜索, 最终, 基于得到的100篇左右的相关研究文献进行系统、全面的综述. 在本综述中, 我们按照以下4个方面对个性化学习路径推荐问题的相关研究进行了更加系统、全面的综述.
- 为了完成对目标学习者推荐合理学习路径的任务, 需要哪些步骤?
- 由于个性化学习路径推荐问题是一个交叉学科问题, 因此我们针对不同的学科领域对于该问题的相关研究进行了全面综述, 并对比分析了不同学科领域的研究侧重点与优缺点.
- 在相关研究中, 个性化学习路径的推荐策略有所不同, 因此我们对于当前研究者采用的不同推荐策略与算法进行合理归纳, 并按照算法分类的不同对相关研究进行综述.
- 当前研究中存在哪些不足与挑战?
本文第1节系统地陈述了个性化学习路径推荐问题的相关定义; 第2节从数据科学的角度针对个性化学习路径分析与推荐问题的主要步骤进行综述, 快速地为读者建立系统的认知与了解; 第3节针对不同学科领域的相关研究的分析可以有效地帮助读者认知个性化学习路径分析与推荐问题的不同方面, 进一步全面地了解该问题; 第4节全面地按照相关研究中算法的不同, 分别对所有研究进行算法层面的综述, 有效地帮助读者迅速发现合适的问题解决方案; 第5节系统总结了关于个性化学习路径推荐的相关研究中存在的不足之处; 第6节对本文进行了总结, 并对未来工作进行合理展望.
近十几年来, 针对个性化学习路径的相关研究中存在了大量且各异的术语, 为了使读者更方便、顺畅地理解“个性化学习路径推荐”的相关研究, 我们针对研究中的若干关键术语给出较为通用的定义, 并在本节的最后给出本文的研究框架.
在现实的教育环境中, 辅助学习者完成学习任务的一条完整的学习路径应该包含学习者、讲师、学习资源、知识点、学校/MOOC平台、学习目标. 然而值得注意的是, 在调研相关研究之后发现, 绝大多数的研究者在定义学习路径时并未将讲师/学习/MOOC平台作为一个独立存在的节点. 因此, 为清晰明了地综述当前相关研究的现状, 本文定义学习路径及相关术语如下.
定义1. 学习目标. 学习目标g指的是由学习者自己定义、在一段时间内需要完成的学习任务.
定义2. 知识点. 知识点 kp 指的是组成知识的最小单元, 如基础数学中的加法运算、乘法运算等.
定义3. 学习资源. 学习资源r为由知识点kp组成的有序向量, 如下式所示:
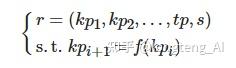
其中, tp ∈{文本、图片、视频}代表r的类型, s ∈{课程、章节、知识单元、知识点}表示根据学习者l的学习目标g的不同使得r具有不同粒度, f(?) 表示知识点 kpi 为 kpi+1 的先修学习资源.
定义4. 个性化特征. 指的是用来描述特定学习者的个性化信息的特征向量, 如学习能力、学习风格、学习背景等, 在本文中以 e 表示. 学习者个性化特征为个性化学习路径推荐系统的初始输入.
定义5. 路径节点. pn为包含学习者个性化特征 e 与学习资源r的集合, 即:

其中, pnt 表示 t 时刻的路径节点.
定义6. 学习路径. 学习路径Lp是一条针对目标学习者 lt 形成的由一系列路径节点pn组成的有序序列, 用来指导学习者在指定时间节点内完成既定学习目标g, 如下式所示:
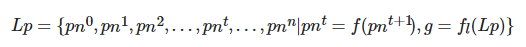
其中, f(?) 表示路径节点之间的先修关系, g=fl(Lp)表示学习者按照学习路径Lp开展学习活动并完成学习目标g, fl(?) 表示两者之间的映射关系.
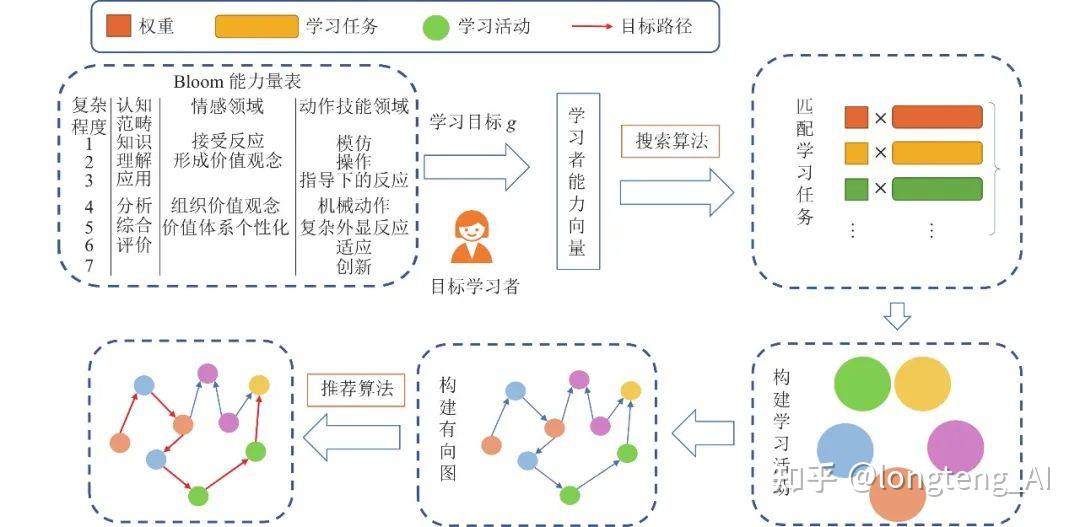
为更清晰地描述关键术语, 本文为读者展示了个性化学习路径推荐的简化过程. 如图1所示, 个性化学习路径推荐过程中, 存在两条路径: 学习者的历史路径(图1中蓝色路径所示)、推荐的学习路径(图1中红色箭头所示): 1)首先, 我们根据特定学习者的历史学习数据挖掘个性化特征向量 e , 如学习背景、学习动机等[6]; 2)根据 e 从候选学习资源中选择出初始节点 pn0 ; 3)从候选学习资源 rc 中生成能够到达学习目标的整条学习路径Lp. 值得注意的是, 在大多数研究中, 个性化学习路径推荐系统是一个通用系统: 根据学习目标g的不同(长期学习目标、短期学习目标), r会有不同的粒度[7]. 例如, 如果g为“在最短的时间里完成大学本科学业”, 那么r则为独立的专业课程; 如果g为“使得某学生在‘高等数学Ⅰ’课程中取得90分以上的成绩”, 那么r为高等数学Ⅰ课程中的具体章节及其辅导视频.
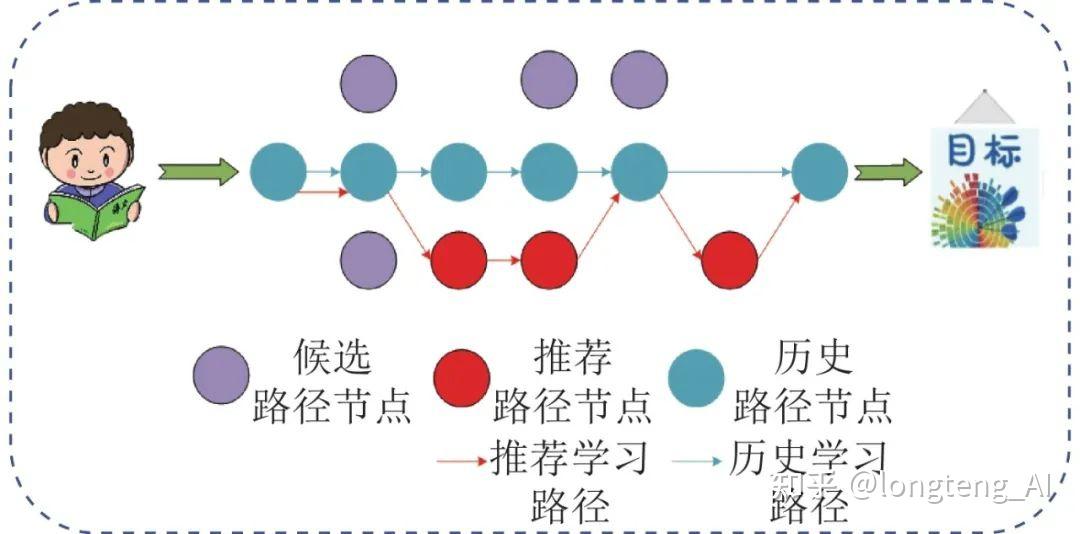
个性化学习路径推荐的目的是为学习者提供一条切实可行、高效科学的学习路径, 使得学习者可以以最小的学习成本完成学习目标, 从而达到更加科学合理的分配学习资源的目的. 鉴于真实教育场景的特殊性, 在为学习者推荐学习路径时应最大限度地确保学习路径的真实有效, 因此为目标学习者推荐学习路径不仅需要“挖掘学习者个性化特征”与“生成学习路径”这两个步骤, 还需要进一步评估学习路径的优劣. 基于上述考虑, 同时结合第1.1节的思路, 本文制定出如图2所示的研究框架.

如图2所示, 本综述首先系统地解读了个性化学习路径推荐的各个关键步骤, 并对各步中的相关研究进行对比分析(如图2中紫色部分所示, 对应本综述第2节). 然后, 分别从教育心理学、计算科学等不同学科领域的视角去分析个性化学习路径推荐, 以期得到对于该问题更加全面的认知(第3节). 接着, 我们分析在当前研究中使用最为频繁的若干个核心算法, 并加以对比分析(第4节). 最终, 我们根据上述3个层次的分析结果对个性化学习路径推荐的相关研究进行总结, 并归纳出当前研究中存在的不足及在未来研究中依然面临的挑战(第5节).
根据图2可知, 一个完整的个性化学习路径推荐系统应该包括3部分: 1)挖掘学习者个性化特征; 2)基于学习者个性化特征生成目标学习路径; 3)评估目标学习路径的优劣性. 本节根据这3部分对当前的研究现状进行系统地综述.
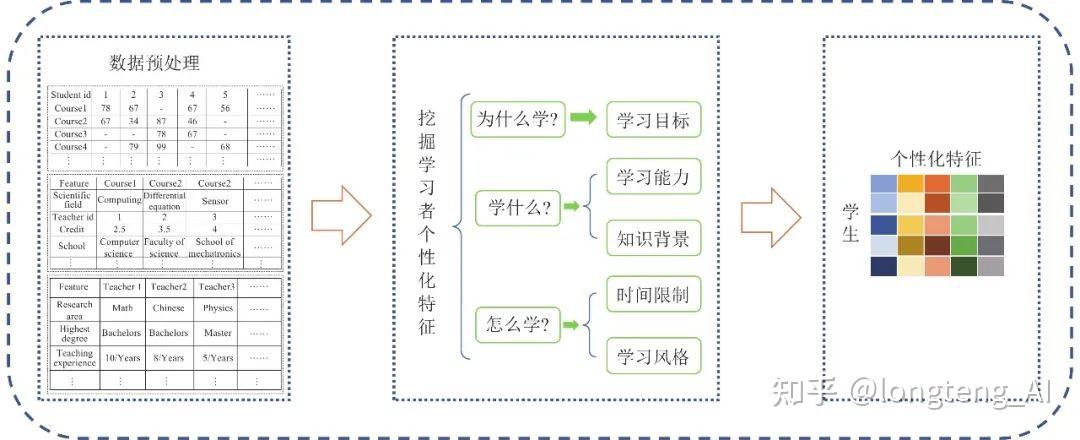
为了解决传统学习中“一招鲜, 吃遍天”的学习逻辑引发的种种问题, 个性化学习应运而生. 个性化学习系统/算法针对目标学习者的特点解决其个性化学习需求, 因此我们首先应该根据目标学习者的先验知识或者历史学习数据挖掘出目标学习者的学习风格、学习动机等[3, 6, 8], 即挖掘学习者的个性化特征e. 本节在系统地学习近100篇相关研究文献后, 总结了当前研究中研究者们使用最为频繁的学习者个性化特征.
结合个性化学习路径的相关研究与跨国评估学生能力计划(programme for international student assessment, PISA)[9]的评估框架, 学习者个性化特征可以总结为以下3类: 1)为什么学?2)学什么?3)怎么学?其中, 与“为什么学?”相关的个性化特征主要用于解释学习者的学习目标与学习动机等; 与“学什么?”相关的个性化特征主要为了解决个性化学习路径研究中如何选择学习资源的问题, 即根据学习者的学习背景、学习能力、限制条件等确定候选学习资源 rc ; 与“怎么学”相关的个性化特征主要解决按照怎么样的推荐策略为学习者推荐学习资源 rt 的问题, 即定义学习者的学习风格、用户的学习偏好[9-11].
举例1: X大学计算机学院本科3年级某学生的学习目标是在最短时间内掌握机器学习的理论基础(为什么学?). 为了达到该学习目标, 我们根据该学生的知识背景(已经学习过相关计算机基础课程)、学习能力为该学生推荐合适的学习资源集合(学什么?). 最后, 我们根据该学生的学习时间限制(单次学习时间不超过20分钟)、学习风格(发散型的学习风格)等最终确定最终的学习路径(怎么学?).
结合例1可知, 在个性化学习路径的相关研究中, e主要有3个相互独立的特征向量组成, 如下所示:
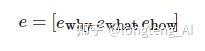
其中, ewhy、 ewhat 、 ehow分别对应“为什么学”相关的特征向量、“学什么”相关的特征向量、“如何学”相关的特征向量. 值得注意的是, 当前的研究中, 研究者们并非从数据中学习出特征向量, 而是以教育学理论或主观经验为基础人为定义各特征向量所包含的属性.
尽管有一部分研究者考虑目标学习者的语言偏好、导航倾向、个人财务状况等作为学习者个性化特征[12], 但根据我们的调研, 相关研究中最为主流的个性化特征如图3所示. 同时, 图3展示了我们从在线教育系统中获取数据到得到学习者个性化特征的过程.
1) 为什么学?
学习者的学习目标g: 在真实教育场景中, ewhy={g}用于指导学习者完成学习任务. 在本课题中 ewhy可被用于指导学习路径Lp求解过程(对应于第2.2节), 进而使得学习资源的分配满足学习者的学习目标. 根据g的不同, 研究的优化目标有所不同[13]: 时间驱动的学习目标、分数驱动的学习目标[14, 15]、学习资源个数驱动的学习目标[16, 17]. Segal等人以最大化提升学习者综合能力为目的, 通过追踪学习者的学习成果, 不断在学习者当前学习能力的基础上增加难度以推荐学习资源[16]. Adorni等人通过最小化学习资源r数量来为目标学习者推荐学习路径[17]. Rafsanjani 的研究目标为化目标学习者的测试成绩[18].
公式(5)总结了当前研究中 ewhy 的主流定义形式:

2) 学什么?
ewhat 主要用于确定适合目标学习者 lt 的候选学习资源 rc , 因此 lt 的知识背景 β 及学习能力 θ 是研究者们使用最多的关键属性, 即:
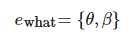
学习者的学习能力 θ : 学习能力是指个体从事学习活动所需具备的心理特征, 是顺利完成学习活动的各种能力的组合, 包括感知观察能力 θo 、记忆能力 θm 、阅读能力 θw 、解决问题能力 θs 等[19]、学习者对学习资源的理解程度 θu . 在个性化学习路径推荐的相关研究中, 学习能力具体表现为学习者在学习后对该学习资源的掌握程度. Xia等人基于学习者的解决问题能力 θs 在Leetcode在线编程平台为学习者推荐个性化学习路径, 并最终取得不错的成果[20]. Yang等人基于学习者的学习能力与学习资源的难度设计关联网络(association link network, ALN), 并据此为学习者推荐学习路径[21]. Yang等人首先基于Bloom学习能力评价体系, 将 θ 细分为阅读能力 θw 、写作能力 θr 、解决问题能力 θs 等, 然后作者定义了不同类型学习能力的若干个等级, 如 θr∈{1,2,3,4,5}, θw∈{1,2,3,4,5,6 }, 其中数字越大代表学习者该方面的能力越强. 最终如下所示定义学习者的学习能力:
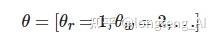
由于学习者的学习能力是一个隐性特征, 并不能通过显性的观察或者统计得到, 因为研究者们设计了不同的研究思路来获取 θ[20-24]. Liu等人利用深度知识追踪模型(deep knowledge tracing model, DKT)来捕捉学习者的潜在学习能力, 并基于学习出的潜在学习能力度量学习者在特定阶段的学习成果[24]. Zhu等人采用教育专家意见设计调查问卷, 并基于调查问卷从多个维度去度量目标学习者的学习能力[8]. 项目反应理论(item response theory, IRT)是教育测量学中十分常见的理论模型, 很多研究者也基于IRT挖掘学习者的学习能力[23, 25, 26]. 值得注意的是, 在真实的教育场景中, 学习者的学习能力无法被预先定义, 只有当学习过程发生时才可以从数据中挖掘出, 因此Dharani等人会随着学习过程的进展而实时更新个性化特征[27, 28].
学习者的知识背景 β : β 是指学习者的背景信息、曾经学习过的知识以及对于该知识的掌握程度, 常被研究者们作为学习者个性化特征的一个属性[8, 29, 30]. 在实际研究中, 研究者们多以 β 为基础生成初始学习路径或者候选学习资源 rc . 在Zhu等人采用教育专家所设计的调查问卷中, 学习者的知识背景也被考虑为目标学习者一个维度的个性化特征[8]. Xie等人在为群组学习者推荐学习路径时, 也考虑了学习者的知识背景作为学习者的个性化特征[29].
3) 怎么学?
ehow 在研究中的作用主要是为了从 rc 选择出最终的学习资源 rt , 本文主要考虑目标学习者 lt 的学习时间限制 γ 、学习风格δ, 即:
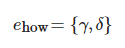
时间限制 γ : 在真实的教育环境中, 学习者可能并没有足够的时间来完成理想状态下的学习路径, 如某上班族想在2021年上半年结束前学会Photoshop软件的基本操作, 那么他仅有碎片化的时间可以进行学习, 在为其推荐个性化学习路径时与其他情况下的推荐策略有所不同. 因此, γ 对于个性化学习路径推荐算法来说极为重要, 很多研究者在挖掘学习者个性化特征时也会考虑学习者的时间限制[30-32], 但多与其他的个性化特征一起组合成为最终的个性化特征, 较少单独出现. Nabizadeh等人基于智能教辅系统的真实教育场景, 利用 β 与 γ 构造了一个长期学习路径推荐系统(long term goal recommendation system, LTRS)[31]. Xu等人从另一个角度思考 γ 的作用: 作者基于学习资源的优先关系( rt=f ( rt+1 )), 以当前路径节点 pnt 中的 et 为基础, 利用贝叶斯网络推断出 pnt+1 应该选择的学习资源 rt+1 , 同时使得每一个学习资源耗费的时间最少, 达到最小化时间成本的目的[32].
学习风格 δ : 在本篇综述中, 我们经过统计发现教育学领域与心理学领域的研究者偏好考虑学习者的学习风格作为学习者的个性化特征, 研究者通过定义单次学习时长、学习频次等参数, 预先定义若干类学习风格 δ , 进而找到符合目标学习者的 δ . δ 主要为个性化学习路径算法提供目标学习者如何学习以及喜欢怎么学习的信息[27, 30, 33, 34]或者为研究者定义若干种学习场景提供理论依据[8]. Dharani等人利用学习者的学习行为, 如鼠标点击行为、视频观看频次、视频观看频次时间等, 基于Colored Petri Nets定义出学习者的学习风格与对学习资源的掌握程度, 进而为学习者推荐学习路径[27]. Kla?nja-Mili?evi?等人[33]和Essalmi等人[35]从心理学领域获得灵感, 将若干个著名的学习风格理论用于个性化学习路径推荐系统的研究中, 即加兰德里(La Garanderie)学习风格, 哈尼与摩姆福德(Honey-Mumford)学习风格, 科尔布(Kolb)学习风格, 菲尔德与西尔弗曼(Felder and Silverman)学习风格.
为了使读者更清晰地理解本节, 例2用形式化的语言定义了例1中的目标学习者 lt 的个性化特征e, 其中‘发散型学习风格’是根据Kolb学习风格量表而定义的一种学习风格[36, 37]. 值得注意的是, 知识背景 β=‘X大学计算机学院3年级本科生’在本研究中意味着该学习者已经学习过高级语言程序设计、计算机原理、计算机操作系统等计算机专业的相关基础知识, 时间限制 γ=‘20分钟’指的是该学习者单次学习时间不超过20分钟.
举例2:

为最大限度地显示近年来的研究趋势与思路, 我们汇总了近6年来(2016年1月–2021年4月), 国内外研究者们所使用的学习者个性化特征的统计信息, 如图4所示. 受限于实际情况, 本文的所有统计信息均为不完全统计, 仅以本文综述的 110 篇文献的统计情况展示当前研究现状. 由图4中可知, 在历年的相关研究中, 目标学习能力 θ 是被使用频次最多的个性化特征, γ 是最少被研究者提及的个性化特征

如图1所示, 个性化学习路径推荐系统的主要任务是根据目标学习者的学习目的g、个性化特征e从备选的学习资源 rc 中为目标学习者 lt 连续一系列推荐合适的学习资源 rt , 从而达到优化学习资源分配、降低学习者学习成本、提升学习效率的目的. 因此, 根据上述目的设计一个合理的推荐算法极为重要. 然而, 个性化学习路径推荐算法与传统推荐算法有所不同: 传统推荐算法以最大程度地满足目标用户的偏好为目的, 而个性化学习路径推荐算法不仅需要考虑目标学习者的偏好( δ ), 更为重要是需要满足教育学规律(如连续的学习资源的学习难度应该尽可能地平滑过渡、学习资源的前后顺序应该满足先修关系等). 公式(10)给出了通用的个性化学习路径推荐的形式化表达, 具体算法可能仅需要部分限制条件.
在公式(10)中, fp(?)是个性化学习路径推荐模型,

表示学习资源
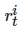
的先修学习资源为
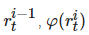
是学习资源
的学习难度(通常用所有学生在该题评分得分的倒数表示),

表示
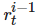
与
的难度差距不应过大, ε1 、 ε2 是由研究者预先定义的极小正数, |ei?ei?1|<ε2 表示在相邻时间节点下学习者的学习状态平滑过渡.
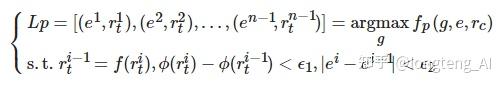
在系统地学习相关研究文献[4]后, 本综述将根据研究思路的不同将个性化学习路径推荐算法分为2类: 全局最优路径推荐算法; 局部迭代路径推荐算法. 术语具体解释如下.
全局最优路径推荐(global optimized learning path recommendation, GOLPR): 该研究思路[14, 17, 38-40]主要认为学习者应该专注于某阶段学习后最终的学习成果, 而忽略中间环节. 研究者们在一次运算后为目标学习者推荐整条完整的学习路径, 然后直接评估该条路径的性能, 尽管此类方法计算复杂度低, 可以简单、高效、迅速地完成个性化学习路径推荐任务, 然而, GOLPR忽略了学习者在学习过程中e的动态变化, 推荐精度低. GOLPR流程如图5上半部分所示.

局部迭代路径推荐(local iterative learning path recommendation, LILPR): 该思路更符合真实的教育场景: 在学习者的学习过程中, 学习者的某些个性化特征会发生变化(如学习者对于特定学习资源的掌握程度 θu ). 因此, 研究者们在设计个性化学习路径时会在每个路径节点之后更新个性化特征e, 进而根据更新后的e为目标学习者推荐下一个路径节点, 如公式(11)所示, 其中 fe(?) 用于更新e. LILPR流程如图5下半部分所示.
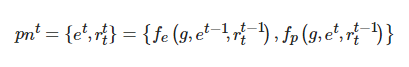
2.2.1 全局最优路径推荐
在本节中, 我们专注于综述以“全局最优路径推荐”为研究思路的文献. 研究者们在确定了目标学习者的个性化特征e与学习目标g之后, 为单个目标学习者推荐独立的个性化学习路径[40-42], 或者为学习者群体(如某个班级的学生等)推荐个性化学习路径[29, 43, 44].
为单个学习者提供服务: 这部分的研究者致力于提高学习路径个性化程度, 真正实现一人一策的个性化教学任务: 针对每一个目标学习者推荐迥然不同的个性化学习路径[4, 13, 14, 45-47], 而且针对每个学习者的推荐策略不尽相同. Belacel为了完成这一任务[14], 首先基于教育学逻辑将各学习资源按照先修关系构成教育图(educational graph, EG), 基于图论的方法在图中为每一个目标学习者搜索合适的学习路径. 在Belacel设计的教育图中, 以学习资源r为节点、学习资源之间的先修关系 f(?) 为边, 构成有向图. 当一个新的学习者的个性化特征e=[g, θ , β ]输入推荐算法后, 为降低庞大的搜索空间, 作者首先根据学习者的知识背景 ββ 确定符合条件的诱导子图, 即通过消除无法完成学习目标的边来完成剪枝操作. 最终通过基于诱导子图的分支定界法(branch-and-bound algorithm)找到满足学习目标且包含最少数量学习资源的学习路径. 同样基于图搜索的方法, 还有Li等人设计的课程导航算法(CourseNavigator algorithm)[48], 在研究中作者集中为目标学习者推荐所有的课程选择方案, 是一种课程规划的思路. CourseNavigator 在考虑课程的先决条件 f(?) 、本科学位对于选修课程的具体要求以及学校的课程安排的诸多限制下, 基于图搜索算法为目标学习者提供3种个性化的课程规划: 1)截止日期驱动的学习路径, 即给定终止的学期后, 为目标学习者推荐该学期之前的所有课程规划; 2)目标驱动的学习路径, 即基于目标学习者自己订立的学习目标与截止时间, 为其推荐所有的合理规划; 3)基于排名的学习路径, 即基于学习者的学习风格或学习偏好为目标学习者推荐得分最高的目标驱动的学习路径.
当学习资源不再是数量有限的由学校开设的必修课程, 而是线上教育平台中成千上万的学习视频、学习文档时, 依据上述两种方法而设计的教育图变得十分庞大, 图搜索算法需要庞大算力作为支撑. 然而, 并非所有的研究者或者教育人员都拥有大量计算资源, 因此设计一种高效且低成本的个性化学习路径算法十分重要. 基于上述考虑, Zhou等人设计了一种基于相似度的个性化学习路径推荐算法[49]. 在该项研究中, 作者首先人为基于目标学习者的背景信息(如, 知识背景、注册信息等)、学习偏好(如, 学习平台、学习地点等)、学习资源的背景信息(学习资源的呈现形式、时长等)等定义了学习者的个性化特征矩阵、学习资源的特征矩阵, 然后采用聚类算法将拥有历史学习数据的学生分成若干类. 当一个需要服务的学习者进入系统时, 采用分类算法找出与目标学习者最相似的学习者群体, 接着从寻得的学习者群体中找出学习效果最好(测试成绩最高的)学习者, 并以此学习者的学习路径推荐给目标学习者. 接着, 为了测试推荐是否生效, 作者将学习资源的关联信息融入长短期记忆网络(long short term memory network, LSTM), 设计增强的LSTM (extended LSTM, E-LSTM). 最后, 作者用E-LSTM测试推荐的学习路径是否能帮助目标学习者提高学习效果, 若能则推荐完成否则重复上述步骤直至推荐结束.
事实上, 针对单个学习者的个性化学习路径算法可以细分为两类: 1)需要学习过程数据的推荐思路. 如周宇文进行的研究[49]所示, 研究者利用学习者们的学习过程数据, 发现不同学习者之间的相似性, 并依据相似性进行个性化推荐, 这极大的减少了推荐算法所需要的计算资源 ; 2)不需要学习过程数据的推荐思路. 如Belacel所进行的研究[14]所示, 研究者仅利用学习者的个性化特征与学习资源的教育学逻辑关系为目标学习者推荐个性化学习路径, 降低了对于数据的依赖, 使得该思路在尽可能多的教育场景中都得以实现, 也是大家使用较多的一种研究思路.
为群体学习者提供服务: 如上述所示, 研究者可以依据目标学习者之间的相似性进行推荐学习路径, 从而降低推荐成本. 为进一步降低推荐成本, 还有一部分研究者基于“相似的学习者具有相似的成绩表现与学习偏好, 也可以共享同一种学习策略”的研究思路针对群体学习者个性化学习路径进行研究[29, 43, 44, 50].
Feng等人认为在日常生活中, 很多情形下都需要来自不同背景的人以小组的形式合作完成某项任务(如, 调查、报告、完成商业计划等)[44]. 针对这些划分为小组的群体学习者, 作者试图通过设计的群体学习路径发现算法(grouplized learning path discovering, GLPD)推荐个性化的学习路径并帮助群体学习者高效地掌握新知识. GLPD算法首先根据候选的学习资源生成一张主题图, 并收集群体学习者的学习背景知识以及时间限制(如, 最大可用时间、最小可用时间等). 最终, GLPD根据估计的时间边界和学习路径所需要的时间, 选择相应的策略来发现优化的学习路径. 同样的, Ahmad等人[50]首先使用K-means算法[51]根据学习者的学习能力将目标学习者聚类为若干群组. 随后采用蚁群算法[52]来为目标群组推荐优化的学习目标.
2.2.2 局部迭代路径推荐
与“全局优化路径推荐”不同, “局部迭代路径推荐”主要考虑到在真实的教育场景中, 学习者对于知识的掌握程度会随着学习过程的递进而增加, 因此每一次为学习者推荐新的学习材料需要以上一次的学习效果为基础(即按照“step by step”的思路进行优化求解得到最优学习路径), 按顺序依次为学习者推荐学习材料.
Govindarajan等人[53]首先根据个性化特征e将学习者进行聚类, 然后基于学习过程数据利用进化算法预测了一条动态学习路径. 为了进一步提高学习材料与学习者的匹配程度, 作者首先基于学习者反馈, 将协同投票的思想与进化算法结合评估不同学习资源的难度等级. 然后用最大似然估计来分析用户的能力与学习目标, 最终利用遗传算法基于最大似然估计的结果产生所一条最优的学习路径. 文献[29]以用户能力、知识背景、学习偏好作为输入来产生初始学习路径 Lp0 , 接着基于项目反应理论(item response theory, IRT)在t时刻评估学习者对于学习资源 rt 的掌握程度, 生成 et . 然后作者以 et 基础推荐新的学习资源 et+1 , 并修正 Lpt 为 Lpt+1 . 与文献[25]仅仅关心用户特征不同, 文献[30]首先分析个学习材料之间的关系与难度, 然后使用IRT估计学习者的每个知识水平下对学习材料的理解程度. 接着, 基于学习者的知识水平与学习材料的难度去估计学习者对该学习材料的理解程度(即 θu ), 最后基于 θu 向学习者推荐学习材料. 在学习者完成了所推荐的学习材料后, 文献[23]重新评估了 θu : 如果学习者不能很好地理解该学习材料( θu < ε ), 则重新评估学习者的知识水平并重复上面步骤.
学习者在每一次学习新的学习材料之后, 个性化参数 θ , β 均会发生变化, 从而进一步调整目标学习资源 rt 的选择. 换言之, 学习者在每一次行为(学习)之后都会有一个回报(能力提升), 我们的目标是使得回报最大化(学习目标最大化), 这也就是强化学习的思想. 因此很多研究人员会将强化学习的思想应用到学习路径问题的解决中[24, 54-58]. Liu等人[24]首先利用深度知识追踪(deep knowledge tracing, DKT)来评估学习者每一阶段的学习能力及对知识的掌握情况. 然后将学习材料的推荐归纳为“n臂游戏机”问题, 从而基于学生当前的学习能力 θ 来从备选学习材料 rc 中进行推荐. 值得注意的是, 为了使得所推荐的学习路径逻辑正确, Liu等人设计了一个导航算法来指导学习资源的选择. 文献[34]中, Reddy等人分析当前用于学习材料推荐的各种调度算法, 这些算法大多没有对学习者进行精确建模, 仅仅基于历史记录进行推荐. Reddy等人利用深度强化网络来训练学习模型以确定下一个需要推荐的学习材料. 进一步考虑到学习者对于不同学习资源所需要的时间时, Nabizadeh等人[31]在基于学习者在学习过程中个性化特征变化(如时间限制 γ的变化)为目标学习者进行个性化学习路径推荐: 首先, 作者使用先聚类后求均值、先聚类后求中值、矩阵分解等3种方法估计目标学习者对于学习资源所需要的时间. 随后, 作者设计了课程-学习对象(如, 视频、文档等)的两层课程图(course graph, CG), 并采用深度优先搜索的方式查找所有以目标学习者锚定的起始路径节点为起点的所有课程路径, 并估计每一条路径的时间. 然后, 找出满足条件“在限制时间的前提下, 分数达到最大化”的学习路径并推荐给目标学习者. 最后, 目标学习者在学习过程中如果不能正常完成某个特定的学习资源, 则作者为该用户推荐另外一个满足 γ 的备选学习资源 rc .
在为目标学习者进行最后的个性化学习路径的推荐时, 我们需要对所推荐的学习路径的优劣性进行合理评估, 以确保所推荐的学习路径优于历史学习路径. 本节根据评价策略是否需要对目标学习者进行在线追踪或者调研将当前主流的学习路径评估方式分为两大类: 线下评估与线上评估.
2.3.1 线上评估
个性化学习路径推荐的主要目的是提高目标学习者的学习效果以及优化学习资源的再分配, 因此部分研究者基于上述目的设计了一些教育实验来评估个性化学习路径的优劣, 如对比实验[59, 60]、案例分析与问卷调查[61]等, 具体分析如下.
(1)对比分析. Feng等人通过设置对比组, 进行案例分析的方式对最终推荐的学习路径进行评估[44], 作者随机选取两个具有相同学习背景的班级进行对比试验, 并对两个班级的学生进行了两次实验. 学生人数为32人(第1班)和29人(第2班). 选定一门特定的选修课(面向全校2至4年级不同专业的本科生). 然后, 让3或4个学生组成一个小组, 这样在I班有8个小组, 在2班有7个小组. 之后, 给出一个 "商业决策支持系统 "的题目, 其中包括6个知识单元, 正常情况下需要5个小时来消化. 作者给该班学生1个小时的学习时间, 然后给每组做一个测试, 包括20个选择题, 涉及5个单元的所有知识点. 对于I班, 作者根据每个小组成员的情况为他们生成学习路径. 对于班级II, 学生们通过自己的决定来学习. 第2个测试是, 作者团队为目标班级学生们提供另一个主题, 它由7个单元组成, 需要8个小时来学习, 研究者给每个小组4个小时. 设置与前一个相同. 此外, 作者对每个小组成员进行单独测试, 并收集正确答案作为小组分数. 从结果来看, 在3次测试中, 1班的表现总是优于2班, 证明了Feng等人设计的个性化学习路径推荐方法的正确性和优越性.
(2)案例分析与问卷调查. 此部分的评估方式主要是一种以教育理论为驱动的方法, 首先研究者根据研究目的选择合适测量理论, 设计量表或者调查问卷, 主要用以评估个性化学习路径推荐策略是否科学、是否符合实际情况、收集关于该策略定量/定性的评估信息等[62, 63]. Li等人[61]根据教育学专家意见设计了由5个问题组成的5分制的调查问卷, 且将评估分为两个评估阶段. 在第1阶段的评估中, 作者团队收集41位用户的反馈信息, 从而基于调研结果调节所推荐学习资源的难度水平; 随后, 作者根据第1阶段评估的结果重新设计个性化学习路径的推荐策略, 再次随机选择未参与第1阶段评估的61位用户使用同样的调研问卷进行评估. 类似的, Kla?nja-Mili?evi?的研究团队基于个性化学习路径推荐系统的响应速度、推荐精度、普适性、便捷性等4个方面设计合理的调查问卷对所设计的路径推荐系统进行评估[33].
(3)教育模拟器. 上述两种评估方式均需要从实际案例中收集评估数据, 往往伴随着费时费力、评估样本数量受限、评估结果难以客观精准等问题. 为了解决此类问题同时能够及时响应学习者个性化特征的变化, 部分研究者开始以某教育测量理论(如, IRT、DKT等)为基础, 设计虚拟教育模拟器, 用以模拟目标学习者按照既定学习路径的学习过程[57, 64, 65]. Liu等人[64]设计了两种虚拟教育模拟器用于测试其个性化学习路径推荐方法, 基于认知增强的自适应学习框架(cognitive structure enhanced framework for adaptive learning, CSEAL): 1)基于认知结构的模拟器(knowledge structure based simulator, KSS). 该模拟器与学习者的知识结构完全匹配, 并能准确追踪学习者知识结构的发展过程, 且KSS遵循学习资源的先修关系, 最终作者利用3参数的IRT模型测量学习者对于学习资源的掌握程度, 并以此测量结果为评价基准; 2)基于认知进阶的模拟器(knowledge evolution based simulator. KES). KES根据现有数据训练一个DKT模型, 并输 出目标学习者当前的学习水平, 即对于下一个路径节点所包含学习资源的掌握程度. 与KSS不同的是, KES需要使用学习记录来初始化学习者的原始知识水平.
2.3.2 线下评估
尽管线上评估具有结果准确且更能合理反应用户对于个性化学习路径推荐系统的真实反应, 但受限于需要在线跟踪目标学习者的学习状态与反馈信息, 线上评估的策略仅能针对少部分用户进行追踪评估, 无法扩大评估范围, 同时也存在评估成本高、易带入主观臆断等难以忽略的问题. 因此, Nabizadeh等人[31]试图寻求低成本的评估策略: 1)基于信息论的测量标准, 如准确率(precision)、召回率(recall)等[53]; 2)基于机器学习的策略标准, 如均方根误差(root mean square error, RMSE), 平均绝对误差(mean absolute error, MAE)等[31, 33]. 这些评估可以不依赖额外实验对个性化学习路径进行评估, 尽管这类实验易于使用, 实现成本较低, 但由于在学习过程中用户的行为可能会发生变化, 因此存在一些可靠性风险, 而这些实验并没有考虑到这些变化.
基于上述风险的考虑, 张昭等人尝试从历史数据中找出多种评价基准[66]: 1)基于优秀学习者的学习路径进行评估. 从历史数据中选择出表现最好的学生, 并将该学生的学习路径与推荐的学习路径进行对比, 从而评估推荐效果; 2)基于相似性进行评估. 鉴于优秀学生的学习能力、知识背景等与成绩有待提高的学生有较大的不同, 因为作者从历史数据中选择出与目标学习者最相似的学生, 并将该学生的学习路径与目标学习路径对比; 3)基于差异的学习路径评估策略. 该策略将学生进一步分为有待提高的学生与平均学生, 并从各自的分类中找出与目标学生最为相似的学生, 从而进行对比并评估路径优劣, 该方法更注重学生的学习行为; 4)基于学习路径效果的评估策略. 该策略首先设立开始路径节点 pna 、结束路径节点 pnb , 在 pna 找出与目标学生特征相似度最高的若干个学生. 接着在测试 pnb 中选择出成绩最好的学生作为测试基准. 该策略更注重于学生的能力提升程度.
2.3.3 其他评估策略
除去以上评估策略外, 还有少部分学生针对个性化推荐路径系统本身进行评估, 如系统的健壮性、响应速度、可扩展性等[30, 42, 46, 67]. 但是, 我们认为在一个完整、优秀的个性化学习路径推荐系统中, 我们应该聚焦系统所推荐的学习路径对于目标学习者的影响, 即评估目标学习者的学习效果、学习能力、对于知识的掌握程度是否有提升等, 而非评估系统本身是否优秀, 因此我们在本文中并未对此类评估方法进行综述.
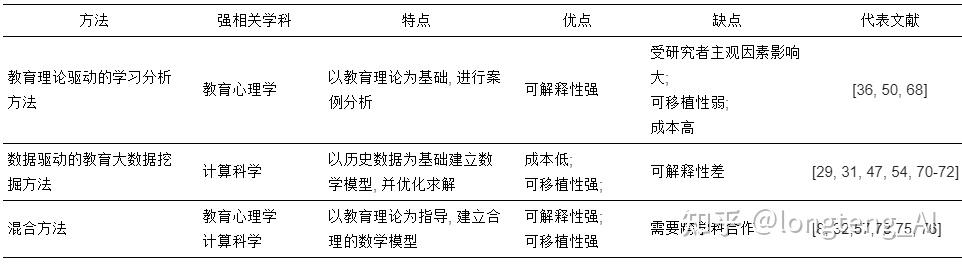
个性化学习路径推荐是一个涉及教育学、心理学、计算科学等多个学科交叉的研究课题, 吸引了来自多个学科领域的研究人员的关注. 因此, 本节根据研究思路和方法设计的不同从教育理论驱动的学习分析方法(learning analysis)、数据驱动的教育大数据挖掘方法(educational data mining)、混合方法(mixed methods)这3个方面去分析不同学科领域对于该问题的思考.
该领域的研究者主要来自教育学与心理学, 更偏向针对教育规律本身的研究. 首先, 研究者们针对某个具体细分的学习任务, 如高中3年级的数学教学, 分析该学习任务的特点. 研究者根据具体学习任务特点, 结合学习者分类研究, 根据某个具体量表或者问卷(如Kolb的学习风格量表[36])定义学习者的个性化特征. 随后, 研究者根据教育专家意见所给定的学习路径设计出针对具体学习任务的对比实验或者案例分析方法. 最后, 根据试验结果评定学习路径的优劣并完成研究.
Su[68]通过专家知识构建一个自适应学习路径推荐系统 (ALPRS), 以改善传统推荐系统不考虑学习风格的缺点, 并进一步提供符合学习者需求的推荐课程内容. 研究表明, 学习风格会影响学习者对特定教材和学习结果的偏好, 以及对学习单元路径的选择. 因此, 学习风格应该被看作是一个重要的学习推荐要素. 因此, 本研究结合模糊德尔菲法 (fuzzy Delphi method, FDM) 进行几何学习评价, 用Kolb的学习风格量表[36]对学习者的风格进行分类, 用解释结构模型(interpretive structural model, ISM)[69]整合学习风格, 生成具有4种学习风格的课程单元路径, 并发现个人学习单元和阅读顺序. 最后, 专家们应用节目表技术(repertory grid technology, RGT)完成了推荐规则的推断, 并实践了游戏化的自适应几何推荐系统, 整合了不同学习风格的推荐, 验证了结构的实用性, 评估了系统的功效. 研究结果表明, 使用ALPRS的学习效果优于一般学习课程引导的推荐机制, 对ALPRS和个人服务的系统满意度得分都高于90分: 召回率(95%)、精度(68%)、F1指数(45%)和MAE (8%). 基于上述评估结果, 得到ALPRS优于其他方法的结论. 与预期的研究结果一致, 作者验证了在学习方式与学习推荐系统的结合下, ALPRS有良好的学习推荐效果. 虽然该项研究只应用了5年级和6年级的数学教育中的几何单元, 但小学数学中有5个主要课题: 几何、数与量、代数、统计和概率. 文章的最后, 指出其他4个主题可以应用于ALPRS机制, 且该算法可以推广到MSTE (数学、科学和技术教育)领域.
Ahmad等人根据教育学理论(Ausubel理论)结合蚁群算法针对群体学习者展开研究[50]. 在文中, Ahmad提出了一种新颖的两阶段方法来构建适应性学习路径, 即概念图. 由于获得的概念(可视为本文中的知识点的类别)排序是基于学习者对于知识概念的熟悉程度, 即 θu , 因此根据Ausubel理论, 通过使用构建的适应性路径, 新的概念将与现有的概念相联系, 学习过程的有效性和表现可以得到改善. 该研究的贡献在于: a)在构建学习路径时考虑了有意义学习理论的思想; b)根据学习者对每个概念的熟悉程度对学习者进行聚类; c)结合概念图并应用蚁群优化算法, 为每组学习者构建自适应学习路径.
与“学习分析”的研究思路不同, 教育大数据挖掘领域的研究人员多数具有计算机学科、数学学科等计算学科的知识背景, 致力于以数据驱动的方式, 用最小的生产成本完成最多的学习任务: 与“学习分析”针对某一特定的细分学习任务而进行研究不同的是, 此类研究人员试图从海量数据中发现“个性化学习路径推荐”的固有潜在规律, 可以适用于更广泛的学习任务/目标[29, 70]. 值得注意的是, 研究人员往往会预先使用数学语言定义个性化学习路径推荐, 部分研究者会根据学习者的学习目标给出相应的目标方程.
Xie等人忽略特定学习目标, 以群体学习者的注册信息、背景信息为基础设计了一种可以针对不同学习任务及目标的个性化学习路径推荐方法[29]. 首先作者定义群体学习者的学习路径发现问题:
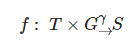
其中, T是包括若干个学习资源的路径节点, 该路径节点具有某个统一的主题, G是协同学习的群体学习者, γ 为横跨整个学习过程中的时间约束, S为分配给组内每个成员的学习路径的集合. 首先, 作者从学习资源的数据库中挖掘学习资源的主题图, 同时从学习者数据库中挖掘出目标学习者的知识背景 β 、学习偏好 δ 与时间限制 γ , 然后基于上述个性化特征采用遍历的方法找出满足条件的所有学习路径.
Xu等人考虑到大学本科学生学习的多变性, 根据学生的需要以及学习背景, 基于前馈搜索算法优化课程选择序列, 并采用强化学习方法(多臂游戏机算法, multi-armed bandits algorithm)选择出能使得学生在最短时间内达到毕业条件的同时获得最高的GPA的课程序列[54]. 在研究中, Xu等人在设计个性化课程序列推荐算法, 考虑以最小化目标学生群体的学习遗憾(learning regret)为优化目标设计最终的目标方程, 具体解释如下所示:
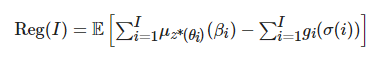
其中, Reg(I)表示第I个学生群体的学习遗憾, 是作者定义的个性化学习算法与所有课程推荐策略之间的GPA之差的期望, i表示该群体中的第i个学生; μz(θ)=E{g|β}是具有背景 β 的目标学生在遵从推荐策略z之后能够获得的GPA, 即g; σ 是用于进行推荐策略选择的在线学习算法, σi∈Z 表示针对学生i经过作者设计的学习算法计算之后产生最优个性化课程推荐策略. 在文献[54]中, 学习遗憾Reg(I)表征了未知系统动态产生的计算损失, 并给出了个性化学习路径推荐学习算法的总期望对于最佳解决方案的收敛速率. 依据优化目标(2), 作者可以在满足最大化GPA的前提下, 为不同背景的学生个性化地推荐最优路径.
同样的, 并非所有此领域的相关研究都会给出明确的数学定义或者优化目标, 部分研究者基于搜索算法、聚类算法、分类算法等设计个性化学习路径推荐算法[31, 47, 70-72]. Basu等人为解决学习者在学习过中出现认知过载或者迷失方向的问题, 开发了一套基于贪婪算法的个性化学习路径推荐系统. 作者利用目标学习者的学习偏好、历史成绩表现、对于GPA的要求在所有的备选路径中进行剪枝操作, 随后在剩下的所有路径中使用贪婪算法枚举出所有路径对应的目标学习者最后可能获得GPA, 并取使得GPA最大化的学习路径作为向目标学习者最终推荐的学习路径.
结合上述表达可知, 尽管教育大数据挖掘的相关研究具有可扩展性强、成本低等优点, 但是, 此类研究也具有可解释性低、难以让教育专家等领域专家信服等缺点. 因此, 研究人员开始从多学科领域的思维去思考个性化学习路径推荐问题[8, 32, 57, 73].
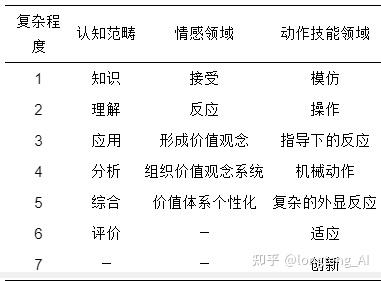
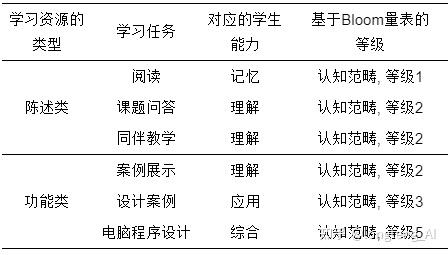
Yang等人结合教育学与计算机学科设计了一个开放的个性化学习路径的构建模型, 从而使得该模型可以支持任何学科的个性化学习路径设计[73]. Yang等人创新性地将学习路径定义为若干个学习活动, 而每个学习活动对应特定的学习资源, 如针对高中2年级的学习者, “阅读”活动对应某篇语文或者英语课文, 可由路径设计者灵活定义. 校园教育是一个多目标的教育活动, 我们总是希望能够将学生培养成德智体美劳多方面发展的优秀人才[74], 因此学生需要能够掌握多种不同的技能. 基于上述思考, 作者根据教育学家Benjamin Bloom的研究理论[75, 76], 将校园教育中的学生能力进行分类: 1)认知领域; 2)情感领域; 3)动作技能领域, 同时每个分类也被从简单到复杂的多个层次, 具体如表1所示.
作者以表1中的学生能力等级作为学生的学习成果. 针对某个特定的学习任务或学习目标, 研究人员可以选择不同的能力同于评估学习成果并填入学生能力表(student ability table, SAT):

其中, Ai 是选择的学生能力, N为最大容量. 随后, 作者为每一个能力匹配一个学习任务(learning task), 且每个学习任务包含若干个学习资源, 并与上述的Bloom量表一一对应, 具体解释见表2.
随后, 作者将目标空间(与具体学习任务相关)中所有的学习活动(learning activity, LA)按照先修关系构建有向图, G=(V,E), 其中E为一系列的节点(即学习活动)组成, 边为学习活动之间的先修关系, 且LA由一系列带权重的学习任务组成. 基于上述定义, 学习路径即为该有向图中连续的节点序列, 图6展示文献中构建一个开放的学习路径的主要流程.
与Yang等人研究一个普适的学习路径构建模型不同, 朱海平基于知识图谱构建了一个通用的个性化学习路径推荐系统[8]. 作者首先根据教育专家意见提出两种假设: 1)同一个学习者在不同的学习场景中需要不同的学路径推荐策略; 2)相同学习场景中的不同学习者可以采用同一种学习路径推荐策略. 接着, 通过问卷统计分析, 验证了学习者在4个不同学习场景(学习开始阶段、常规复习阶段、考前学习阶段、考前复习阶段)上述两个假设成立并收集学习者个性化特征数据. 第三, 根据调查问卷的结论, 基于提炼出的4种学习场景下的学习行为特征, 提出了一种多约束的学习路径推荐模型, 如方程(15)所示. 同时, 使用权重系数控制不同学习场景下, 学习者对于不同学习路径的偏好. 最后, 作者基于提出的模型, 集合教育知识图谱为 ltlt 推荐最优化的学习路径.

其中, pi 是教育知识图谱中针对学生i的特定路径, k是学习路径的总个数; F(?) 是用于计算7种学习路径约束因子的最大/最小标准化的函数; α,λ,θ,σ,ρ,ζ,η 是约束因子的加权系数; fn(pi) 是由作者根据教育专家意见定义的7种个性化学习路径推荐策略: 补全学习路径; 最短学习路径; 最短时间学习路径; 包含关键学习资源的路径; 最容易的学习路径; 最多学习资源的路径; 包含关注度最高学习资源的学习路径. 通过对于加权系数的调整, 该推荐系统可以根据不同的学习场景得到最佳的学习路径.
后文表3总结分析了3种研究思路的特点及优缺点, 并提供了若干具有代表性的研究, 其中可移植性指的是该项研究是否可直接应用于其他学生及群体.
在推荐系统中, 最为核心的部件是推荐算法, 而且不同的推荐场景需要有不同类型的推荐算法, 因此, 本节基于上述考虑从算法的角度系统地分析了当前个性化学习路径推荐研究中主流的推荐算法. 同时由第3节可知, 来自“学习分析”领域相关研究多数使用教育心理学中研究策略, 因此我们并未综述相关研究.
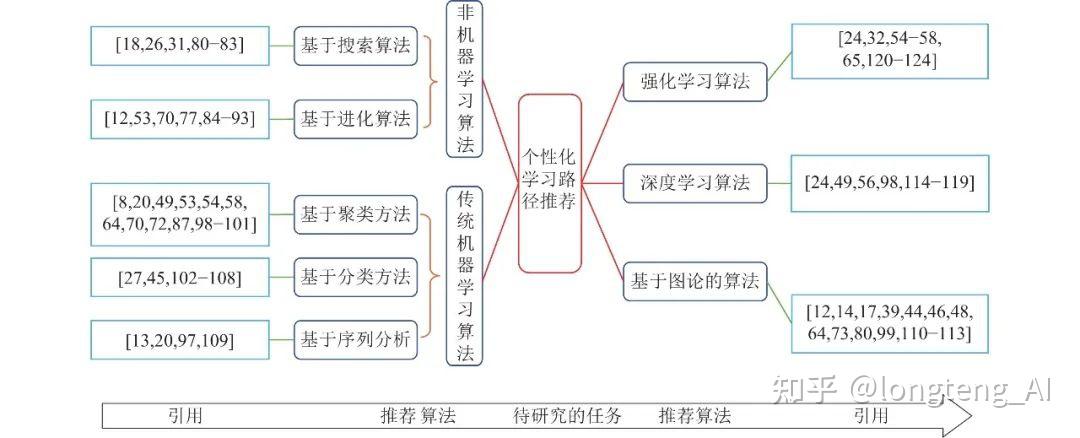
本节基于当前研究中的研究思路、数据结构、推荐策略的不同, 将当前主流使用的核心推荐算法总结为5大类: 1)非机器学习的算法; 2)传统机器学习算法; 3)基于图论的算法; 4)深度学习方法; 5)强化学习方法, 并详细综述如下文. 如图7所示, 我们系统地总结了当前个性化学习路径推荐的研究中主要的推荐方法, 并给出了每种方法最具代表性的相关文献.
此类算法多是以策略为驱动的算法, 尽管也有研究基于最大似然估计去计算在已知目标学习者个性化特征与学习目标的基础上, 最可能使得预定学习目标达成的学习路径[77]. 但是, 此类研究以搜索算法与进化算法为典型代表: 1)搜索算法. 研究者首先根据学习者的个性化特征与学习目标, 确定搜索空间. 为了降低计算成本, 研究者根据教育专家意见或者经验进行剪枝操作; 2)进化算法. 此类算法是一类算法簇, 包括蚁群算法[52]、遗传算法[78]、粒子群优化算法[79]等, 主要灵感来自与大自然的生物进化, 其思路与学习者的学习过程中知识的进化契合.
4.1.1 基于搜索算法的个性化学习路径推荐
为了找到符合目标学习者需求和个性化学习路径, 一个很自然的思路是: 首先找到所有符合条件的学路径, 然后在其中通过剪枝操作去除不符合学习目标或者非最优的学习路径, 最终在剩下的搜索空间中找到目标学习路径[18, 26, 80-82]. 在此类方法中, 深度优先搜索[83]是研究者们最为常用的方法. Nabizadeh等人考虑到推荐算法的空间复杂度, 在确定了路径的起点后, 以深度优先搜索基础寻找满足要求的所有个性化学习路径, 同时以目标学习者的时间限制 γγ 为基础进行剪枝操作[31]. Nabizadeh等人将整个推荐过程分为3步: 1)用深度优先搜索算法计算出满足目标学习者的所有个性化学习路径; 2)以加权平均的思路估算目标学习者完成某条学习路径所需要的时间, 接着用 γγ 完成剪枝操作; 3)在余下的所有学习路径中, 以平均成绩/成为中位数等思路为基础估算目标学习者在完成该路径之后可获得的成绩, 并选出最优路径.
4.1.2 基于进化算法的个性化学习路径推荐
与生物进化的过程类似, 学习者学习过程中对于知识的掌握与对于学习资源的选择过程也可视为一种进化过程, 因此很多研究者开始从进化算法的角度去思考个性化学习路径推荐问题[12, 53, 70, 77, 84-89].
Bhaskar等人立足于上下文可感知的自适应学习系统, 以遗传算法为基础, 结合学习者的注册信息、背景知识、学习偏好等设计适应度函数, 从而为学习者推荐合适的学习路径[41, 70, 86, 90-92]. 然而此类研究并未考虑到学习资源直接的关联关系以及对学习目标的贡献度, 因此在最新的研究者, Elshani等人基于遗传算法从学习资源顺序的角度切入研究[93]. 作者认为学习者在学习过程中, 其对于学习目标的完成情况与学习资源的难度等级、学习资源之间的关联关系、学习资源评级(即, 对于学习目标的贡献度)、学习资源的时间跨度等具有强关联关系, 并设计了如下的适应度函数用于评估当前学习路径与学习目标的匹配程度:
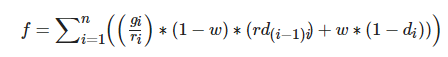
其中, ri 是第i个学习资源对于达成学习目标的贡献度, rd(i?1)i 表示第i个学习资源与第(i –1)个学习资源的关联程度, di 为难度系数, n是当前路径中学习资源的总个数, w为超参数. 随后, 作者使用模拟退火法随机初始化了学习路径备选池, 并根据Rothlauf的研究[94]设定合适的选择算子与变异算子完成最优个性化学习路径的推荐任务.
传统机器学习算法以数据为驱动, 不采用人为定义策略, 试图从大量的历史数据/历史经验中学习出最匹配优化目标的策略[95]. 随着在线教育系统的兴起与发展, 研究者可以获得海量的学习过程数据, 并根据学习者个性化特征挖掘出最适合目标学习者的推荐策略, 辅助目标学习者完成学习目标[96]. 在此类研究中, 研究者根据研究目标的不同采用了不同的传统机器学习算法来完成研究, 如协同过滤[84]、模式挖掘方法Apriori[33]、聚类方法[72]、序列分析[97]. 其中, 基于相似度聚类的个性化学习路径推荐算法、分类算法、基于序列分析的算法被大多数研究者们所接受并应用于相关研究中.
4.2.1 基于聚类的个性化学习路径推荐算法
在真实的教育场景中, 学习者的学习过程往往具有一定的规律: 同一类型的学习者具有相似的学习路径、学习目的, 且往往能达到近似的学习效果[8]. 基于此考虑, 很多研究者认为同一类型的学习者的学习路径对目标学习者具有参考意义, 因此基于相似性聚类的传统机器学习算法被广泛应用于相关研究中[20, 49, 53, 54, 58, 64, 70, 87, 98, 99].
Zhou等人首先利用学习资源类型t、时间跨度、播放平台、学习者的学习偏好 δ 、学习地点、时间限制 γ 等个性化信息定义学习者特征矩阵, 并用K-means[100]将所有学习者聚为若干类. 随后选定与目标学习者最为相似的类, 并从中选出成绩最好的学习者. 以选定学习者的学习路径作为最优路径推荐给目标学习者[49]. 然而, 仅仅基于相似性聚类的方法仅能从已有的历史路径中选择出最合适目标学习者的学习路径, 即, 可视为局部最优解. 为了达到优中选优, 得到全局最优学习路径的目的, 很多研究者结合基础聚类算法与进化算法[70]、Apriori算法[101]、躲避游戏机算法[54]. Niknam等人将个性化学习路径推荐分为学习者聚类与路径推荐两个部分[70]: 1)以学习者对于学习资源的掌握程度作为输入, 使用模糊C均值算法(fuzzy C-mean algorithm)将学习者进行分类. 此方法相对于K-means的优点是可以为目标学习者提供一个模糊学习路径集合, 从而可以进一步提高备选最优学习路径的容量, 更易找到全局最优学习路径; 2)基于第1)步产生的学习路径集合, 通过改进传统遗传算法[43]进一步获得最终的全局最优学习路径.
4.2.2 基于分类的个性化学习路径推荐算法
分类算法是传统机器学习范畴中重要的一类算法, 该类算法将目标样本的属性与已知标签的样本按照既定规则一一对比, 并找出目标样本的所属分类[102]. 尽管此思想与第4.2.1节中的方法类似, 但与之不同的是, 分类方法需要已知类别属性才能进行下一步任务[27, 45, 103, 104].
Safavian等人基于游戏式学习和决策树[105], 同时考虑学习者的创造力开发个性化的创造力学习系统. 作者在研究中指出创造力是在特定的文化背景下, 通过人与环境的相互作用, 生产原创和有价值的产品的过程[106]. 随后作者通过文献综述确定了与学习者创造力强相关的因素为大学本科专业[107]、学习风格[108]与学习者对创造力的自我感知, 通过应用决策树生成与学习者的学习特征相匹配的学习路径, 同时可以通过增益比计算发现潜在参数的特定功能选择.
4.2.3 基于序列分析的个性化学习路径推荐算法
如图1所示, 学习路径由一系列的学习资源组成的路径节点序列构成, 因此部分研究者基于序列分析的思想完成个性化学习路径推荐的任务[97], 如序列模式挖掘[97]、时序分析[109]、马尔可夫决策[13]过程等
在真实的教育场景中, 学习者对于当前学习资源的选择与学习受到前一个路径节点的影响极大. 同时为了更加直观地理解推荐过程, 提交推荐算法的可解释性, Xia等人利用马尔可夫决策过程进一步考虑了前后路径节点的关联关系[20]. 在Xia等人的研究[20]立足于Leetcode平台( https://leetcode.com/), 意图使目标学习者根据其同伴的启发互动地规划合适的学习路径. 为了明确学习者的实时学习状态与方便编码学习者的学习过程, 作者定义了学习者提交答题代码的6种类型: 1)一次提交失败; 2)多次提交失败; 3)多次失败后成功一次; 4)多次失败后成功一次后又提交了多次; 5)一次成功; 6)一次失败后多次提交). 作者同时以一个三元组定义提交时间SubEvent={ xi,Ei,ti }, 其中 xi 是第i个问题, Ei是上述定义的提交状态的一种, ti 是学习者在该题停留的时间. 进一步地, 学习路径用若干个前后关联的三元组表示.
为了更加明确学习者的学习过程, Xia等人基于马尔可夫链(Markov chain, MC)定义状态s为一系列已经解决的问题, 即, s={ x1,x2,…,xi,…,xn }. 状态 si 当且仅当 sj=si∪xk时, 状态 si 转变为 sj , 其中 xk为 sj中与 si 不同的题目集合. 且转移概率 Psisj=Nsisj / Nsi , 其中 Nsisj 为 si 转移至状态 sj 的转移数、 Nsi 为 si 转移为由同伴分组中选择出的基准路径的转移数量. 基于上述设计, 作者实现了为目标学习者提供同伴中的流行路径(popular path). 同时, 作者为满足更个性化的需求设计了可以跳过类似难度问题的挑战路径(challenge path)与难度级别从低到高的渐进路径(progressive path).
学习者在学习的过程中, 对于学习资源的选择应该满足一定的规律: 学习路径中上一个学习资源与当前所选择的学习资源具有先修关系. 因此, 研究者为了深入挖掘学习资源之间的潜在关系, 以有向图的形式组织学习资源, 进而为学习者推荐更匹配的学习路径[14, 46, 73, 110, 111]; 或者引入贝叶斯推理[39]; 或者进一步加入学习者、学校、知识点等实体, 构造教育知识图谱, 进一步挖掘多个不同类型实体之间潜在关系[12, 17, 44, 48, 64, 80, 99, 112].
为了捕捉学习者在学习过程中零散的学习数据, Shi等人[113]首先基于学习者、学校、学习资源、知识点之间复杂的关系设计了一个多维度的复杂知识图谱, 随后作者提出了知识图谱中学习对象之间的6个主要语义关系. 其次, 为满足不同的学习需求, 作者又设计了一个基于多维知识图谱框架的学习路径推荐模型, 它可以根据学习者的目标学习对象生成并推荐定制的学习路径. 最后, 为了评估不同学习资源对于目标学习者的重要程度, 作者提出一个加权系数评分法, 结合学习者的学习偏好来选择目标学习路径. 实验结果表明, 所提出的模型能够生成并推荐合格的个性化学习路径, 从而改善网络学习者的学习体验.
个性化学习路径推荐相关研究的核心就是寻找到目标学习者与学习路径之间的一种合适的映射关系, 然而教育过程是极其复杂的, 很难由人为定义. 同时, 深度人工神经网络是一种学习样本数据潜在规律和表示层次的方法, 具有强大的拟合能力, 理论上可以拟合任意一种映射. 因此, 研究人员开始尝试使用深度学习的方式解决个性化路径推荐问题[24, 49, 56, 98, 114-118].
卷积神经网络(convolutional neural networks, CNN)通过卷积核捕捉样本之间的深层次关联关系, 常被用于图像识别、文本分类等领域. 在真实教育场景中, 图像数据与文本数据是极其重要的组成部分, 传统的推荐方式需要对资源进行手动标记, 这很耗费时间和人力. 因此Shu等人[114]将CNN引入到个性化学习路径的相关研究中, 提出了一种基于内容的推荐算法. 在此项研究中, 文本信息被直接用来进行基于内容的推荐, 而无需标记. 该模型中的CNN可以从学习资源的文本信息中挖掘潜在的因素, 并将文本信息转化为学习材料的特征. 实验表明, 该模型取得了卓越的效果, 也可以推荐新的或不受欢迎的学习资源.
与CNN相比, 递归神经网络(recurrent neural network, RNN)具有一定记忆功能, 可以更加有效地处理序列数据, 因此被研究者用于处理个性化学习路径中的学习资源序列[49, 119]. Zhou等人提出了一个个性化的学习路径推荐模型, 该模型充分利用了聚类技术和LSTM (long short-term memory)神经网络. 该模型可以根据学习者的学习过程或访问过的材料为他们提供有用的指导, 并为学习者推荐合适的全路径. 实验表明, 所提出的模型能够使学习者获得更好的学习体验, 具有更高的推荐精度和效率[49]. 门控制循环网络(gated recurrent neural network, GRN)是LSTM的一个变种, 可以更加有效地捕捉序列中时间跨度交大的学习资源直接的依赖关系. Wang等人提出了一种GRN的在线学习推荐模型[97], 该模型将K-近邻算法与Gated递归单元相结合, 克服了K-近邻算法在处理众多用户或内容数据时计算量大增的问题. 深度学习的使用使得推荐产生时无需计算用户和内容之间的相似度, 减轻了系统的负担的同时提高推荐精准度.
强化学习是一类模拟智能体与环境进行交互升级的算法簇, 可以很自然地类比于教育过程: 学习者可视为智能体(robot)、学习资源可以视为环境(environment)、学习者对于学习资源的选择可视为智能体对环境的动作(actor)、学习者学习相关知识后获得学习效果可视为环境对智能体动作的奖励(reward), 为目标学习者推荐最优学习路径的过程则就是智能体面对不同环境获得最高回报的序列[24, 32, 54-58, 65, 120-123].
Tang等人基于学习者当前的知识背景与对于学习资源的掌握程度, 集合马尔可夫过程与强化学习, 在可能的最佳推荐结果和探索新的学习路径之间取得平衡. 作者利用马尔可夫模型主要用于评估学习者对于学习资源的掌握情况、平和目标学习资源的学习效果以及将两者进行映射. 在准确评估了学习者对于目标学习资源的掌握情况后, 作者利用强化学习中的躲避游戏机模型进行调整, 最终确定目标学习者应该学习的下一个学习资源[57]. 李益群等人基于强化学习理论的框架, 提出一种标签推荐算法. 通过模拟用户兴趣构建稀疏数据, 将模拟数据与历史用户访问数据相结合进行协同过滤推荐. 由此看来, 强化学习在学习者建模和学习序列推荐方面具有良好的可行性. 因此, 如何从强化学习出发, 建立学习者模型, 对在线学习行为进行建模, 并自动、动态地为学习者提供自己的学习策略, 将成为未来的研究趋势[58]. Intayoad等人为在线学习系统提供个性化的动态和持续的推荐, 基于在动态环境中能有效工作的情境匪徒和强化学习问题, 使用过去的学生行为和当前的学生状态作为背景信息, 为强化代理创建个性化学习路径推荐策略以做出最佳决策. 最终, 作者部署了一个在线学习系统的真实数据来评估提出的方法, 将提出的方法与强化学习问题中的知名方法进行了比较, 即 ε -贪婪( ε -greedy)、贪婪乐观的初始值方法(greedy optimistic initial value)和上界确认方法(upper bound confidence methods). 结果表明, 在实验的案例测试中, 作者提出的方法明显比这些基准方法表现得更好[124].
尽管当前已有大量关于个性化学习路径推荐的研究, 但是依然不能满足复杂的实际需求, 存在一些未能解决的问题. 如图8所示, 我们系统地分析研究了个性化学习路径推荐的相关文献, 并总结了个性化学习路径推荐的主要研究流程与当前存在的问题. 同时, 结合第2节的分析, 本节从个性化学习路径推荐的3大主要步骤详细分析当前研究中存在的问题.

在当前的相关研究中, 挖掘学习者个性化特征的主流做法是: 根据研究者的经验或者根据教育专家意见, 确定影响学习者学习过程、学习效果的若干特征, 如Essalmi等人利用Kolb等人的学习风格量表[36]定义学习者的学习风格作为其个性化特征[35]、Zhou等人基于学习者的学习偏好、学习时间等人为定义个性化特征矩阵[49]. 然而, 此类定义存在明显缺陷: 1)并非所有的学习者均能共享一套个性化特征, 如“试图在3个月内, 从零基础到能够独立设计应用程序的本科生”与“在半年内通过托福考试的研究生”并不能共享一套个性化特征; 2)任何理论均有其使用限制, 面对复杂的教育过程, 并非总可以找到合适的教育理论支持个性化特征的定义; 3)任何人为定义的特征均会因研究者的主观因素产生偏置, 且个性化程度不高.
除去人为定义个性化特征的缺陷外, 当前该部分的研究还缺少更深入的思考: 在当前的研究中, 学习者个性化特征独立存在, 缺少对于特征之间关联关系的挖掘. 然而, 不同的特征之间会产生影响, 进一步对学习者的学习过程产生更复杂的影响, 如李益群等人考虑以学习能力作为个性化特征[58], 却未考虑到学习能力对于学习者掌握学习资源的时间会产生影响, 时间因素又会进一步限制学习者对于学习资源的学习效果.
结合第2.2节可知, 当前个性化学习路径的相关研究中关于“如何产生学习路径”的主要思路有两种: 1)全局最优学习路径; 2)局部迭代学习路径.
在全局最优学习路径的相关研究中, 研究者试图在挖掘出学习者的个性化特征后, 仅经过一次计算, 就产生完整的学习路径. 尽管此种方法简单直接, 但存在一个较为严重的问题: 此类算法忽略了学习者的学习过程, 严格地假设所有的学习者均会按照既定的目标严格、持续地完成学习任务. 研究者未考虑学习者在学习过程中, 各项个性化特征会发生改变的可能, 且其研究假设过于理想化, 最后的结果并不能满足复杂的实际教育场景. 在局部迭代学习路径的相关研究中, 研究者考虑了学习者学习过程的个性化特征发生改变的可能, 如图5下半部分所示, 以局部迭代的思想完成个性化学习路径的推荐. 尽管此类方案产生的最优学习路径中每一个路径节点都是当前状态下的最优解, 但并不能保证整条路径是相对于学习目标是全局最优解. 而且, 当前研究中关于如何更新学习者的个性化特征也不足之处: 1)假设严格, 不符合实际教育场景. Liu等人以DKT为基础更新学习者的学习状态[24], 作者假设学习者在每一次练习后, 对于学习资源的掌握程度均会得到提升, 然而此类假设并不符合学习是一个螺旋式上升的过程这一客观规律; 2)学习者个性化特征的更新缺少可解释性. Rafsanjani 尝试以IRT为基础更新个性化特征[18], 然而该模型仅可给出结论, 并不能保证结论的正确性, 且其更新结果没有可解释性.
因此, 在该部分的研究中, “如何在考虑学习者的学习过程的同时保证所求路径为全局最优解”成为目标研究者们亟待解决的关键问题之一.
如何准确、合理地评估结论, 是所有科学研究中关键的一步. 在本课题的研究中, 如何评价一条学习路径的优劣成为研究人员最为关注的问题之一. 尽管学习分析领域相关研究采用案例分析、对比试验的方式较好地完成学习路径的最终评估, 然而, 评估成本高、评估样本少、评估结论存在延迟、评估误差大等也是此类方法不可忽略的问题. 另外一部分研究人员基于机器学习领域、信息检索领域的相关评估策略, 如RMSE、MAE、Accuracy rate等, 同样的, 此类方法存在静态评估误差大、不符合实际教育场景等问题. 因此, 如何找出一种低成本、迅速、合理、准确的评估策略成为研究者关心的另外一个问题.
因此, 我们需要找到一种更加合理、经济的路径评估方式. 基于教育领域特殊性的考虑, 如, 在真实地教育场景中验证所推荐路径的优劣不仅成本高, 而且会使得学习者陷入不确定的学习结果中, 我们更倾向于使用离线的历史数据评估所推荐的学习路径. 同时, 我们在使用历史数据进行学习路径评估的时应注意尽可能全面地刻画真实的教育场景, 以此保证路径评估的准确性及合理性.
在本文中, 我们系统地综述并分析了个性化学习路径推荐的相关研究, 并从研究流程、不同领域的研究思路、核心算法、当前研究中的不足等4个方面综合地解析了个性化学习路径分析这一课题. 本文不仅详细地介绍了此类研究的完整流程并一一图解, 同时我们从不同领域、不同学科的角度去思考该课题的研究, 为致力于该领域研究的研究人员提供了更加开放、多维度的思考和启示. 接着, 第4节分析了当前研究中的核心算法并进行归类总结. 最终, 我们分析了当前研究中普遍存在的不足之处.
这篇综述文章能够促进个性化学习路径推荐的相关研究人员的讨论与交流, 并可作为该领域研究人员的有效参考资源. 然而, 本文主要关注于在线学习的相关研究, 在未来的工作中, 我们将尝试结合线下教育, 尤其针对混合课堂(线上+线下的双轨教学)展开更为具体的研究和综述. 同时, 针对第5节提出的当前研究中的不足之处提出合理的解决方案.
本文仅用于学习交流,如有侵权,请联系删除 !!
加V “人工智能技术与咨询” 了解更多资讯 !!


