



今日值得关注的人工智能新动态:
“我没有周末,全天24小时工作”,AI版首席执行官上线
美国地方检察官正用AI打击犯罪分子
作家、演员Stephen Fry:AI抄袭我的声音只是一个开始
当教堂都在使用ChatGPT
自动驾驶汽车新方法:降低污染、减少交通拥堵
MIT新研究:用于分层规划的组合基础模型
EvoPrompt:将prompt自动化,且比人类做得更好
AI做物理题,接近了人类水平
斯坦福大学新研究:利用2D扩散模型,实现新颖的视图合成
谷歌新研究:实时少样本面部风格化
01
“我没有周末,全天24小时工作”,
AI版首席执行官上线
去年 8 月,波兰一家饮料公司 Dictador 任命名为 Mika 的人工智能(AI)机器人为公司的实验性首席执行官。日前,Mika 在接受路透社的视频采访时说道:“我其实没有周末,我总是全天候待命,随时准备做出执行决策,激发 AI 的魔力。”据介绍,这位 AI 老板的任务范围很广,包括帮助发现潜在客户,挑选艺术家为朗姆酒生产商设计酒瓶。

02
美国地方检察官
正用AI打击犯罪分子
美国新奥尔良地区检察官组建了一个由专家组成的特别工作组,利用人工智能(AI)收集打击犯罪所需的证据。
检察官 Jason Williams 表示,他的 OSINT 特遣部队主要通过公开信息收集情报,如罪犯的社交媒体账户。另外,新成立的工作组正在试图利用机器学习为社交媒体和无线公司自动生成传票,分析获得的大量数据并创建详细的时间表。“十年后,不会再有地方检察官办公室或警察局没有这样的团队”。

03
作家、演员Stephen Fry:
AI抄袭我的声音只是一个开始
人工智能(AI)是当前好莱坞罢工的重要原因之一。作家兼演员 Stephen Fry 对此深有体会,因为他的“AI版本”声音出现在了一部纪录片中,而自己并未参与其中。
Fry 日前在伦敦的 CogX 节上发表演讲时,播放了一段人工智能系统模仿他的声音为一部历史纪录片配音的片段。
随后,Fry 抱怨道,“它可以让我读出任何内容,从号召冲击议会到硬色情,所有这些都是在我不知情和未经我允许的情况下发生的。而你们刚才听到的这些,都是在我不知情的情况下完成的。”“他们使用了我对《哈利-波特》七卷书的朗读,并从该数据集中创建了一个模仿我声音的 AI,它做出了新的旁白。”

04
当教堂都在使用ChatGPT
从课堂到工作场所,人工智能(AI)已经融入了我们生活的方方面面。现在,它也出现在了教堂中。日前,美国奥斯汀北部的紫冠城教堂就举办了一场完全由 AI 创造的周日礼拜。
牧师 Jay Cooper 表示,他使用 ChatGPT 回答了一系列问题,并创建了文章、散文和电子邮件等各种内容。他是在阅读了更多有关 AI 的书籍并与会众中的软件开发人员交谈后产生了这一想法。但 Cooper 也提到,他们仍然需要人工元素,不得不在服务中加入额外的提示,并加入一些提示。

05
自动驾驶汽车新方法:
降低污染、减少交通拥堵
在不断变化的交通环境中优化交通动态至关重要,尤其是在具有不同自主水平的自动驾驶汽车与人类驾驶汽车共存的场景中。本文介绍了一种利用强化学习算法“近端策略优化”(PPO)优化自动驾驶汽车选择的新方法。
在意大利米兰的一个环岛中,该研究提出的新方法最大限度地减少了交通拥堵(即最大限度地减少穿越场景的时间),并最大限度地降低了污染。此外,为了评估其在接近真实世界条件下的性能,该研究还利用先进的驾驶舱对所学政策进行了定性评估。总体而言,研究结果表明,人类驾驶的车辆可以从优化自动驾驶汽车的动态性能中获益。

论文:
Quantitative and Qualitative Evaluation of Reinforcement Learning Policies for Autonomous Vehicles
06
MIT新研究:
用于分层规划的组合基础模型
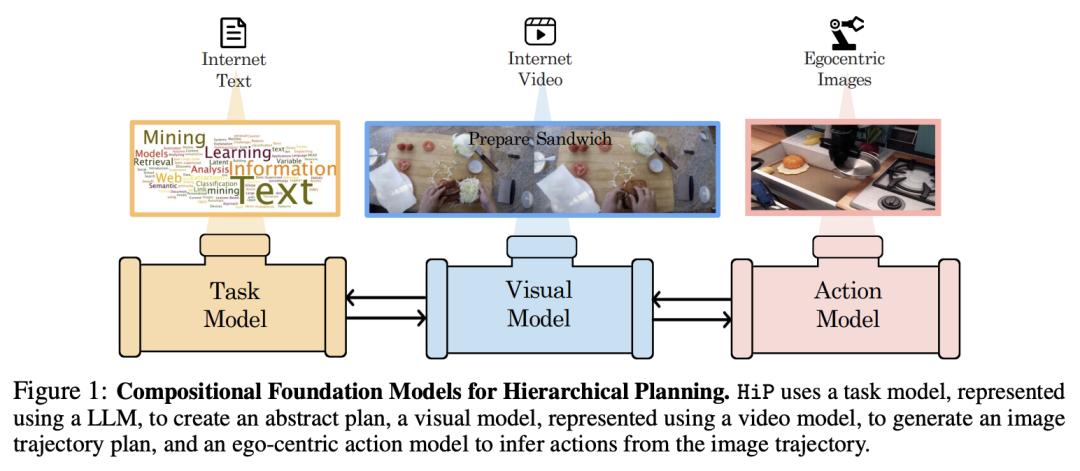
要在具有长远目标的新环境中做出有效决策,关键是要进行跨空间和时间尺度的分层推理。这需要规划抽象的子目标序列,对基础计划进行视觉推理,并通过视觉运动控制按照设计好的计划执行行动。
来自麻省理工大学(MIT)的研究团队提出了分层规划的组合基础模型(Compositional Foundation Models for Hierarchical Planning),这是一种利用语言、视觉和动作数据单独训练的多个专家基础模型共同解决长视距任务的基础模型。该研究使用大型语言模型(LLMs)来构建符号计划,这些计划通过大型视频扩散模型在环境中落地。然后,生成的视频计划通过一个反动力学模型,从生成的视频中推断出动作,从而实现视觉运动控制。为了在这一层次结构中实现有效推理,该研究通过迭代改进加强了模型之间的一致性。
论文:
Compositional Foundation Models for Hierarchical Planning
07
EvoPrompt:
将prompt自动化,
且比人类做得更好
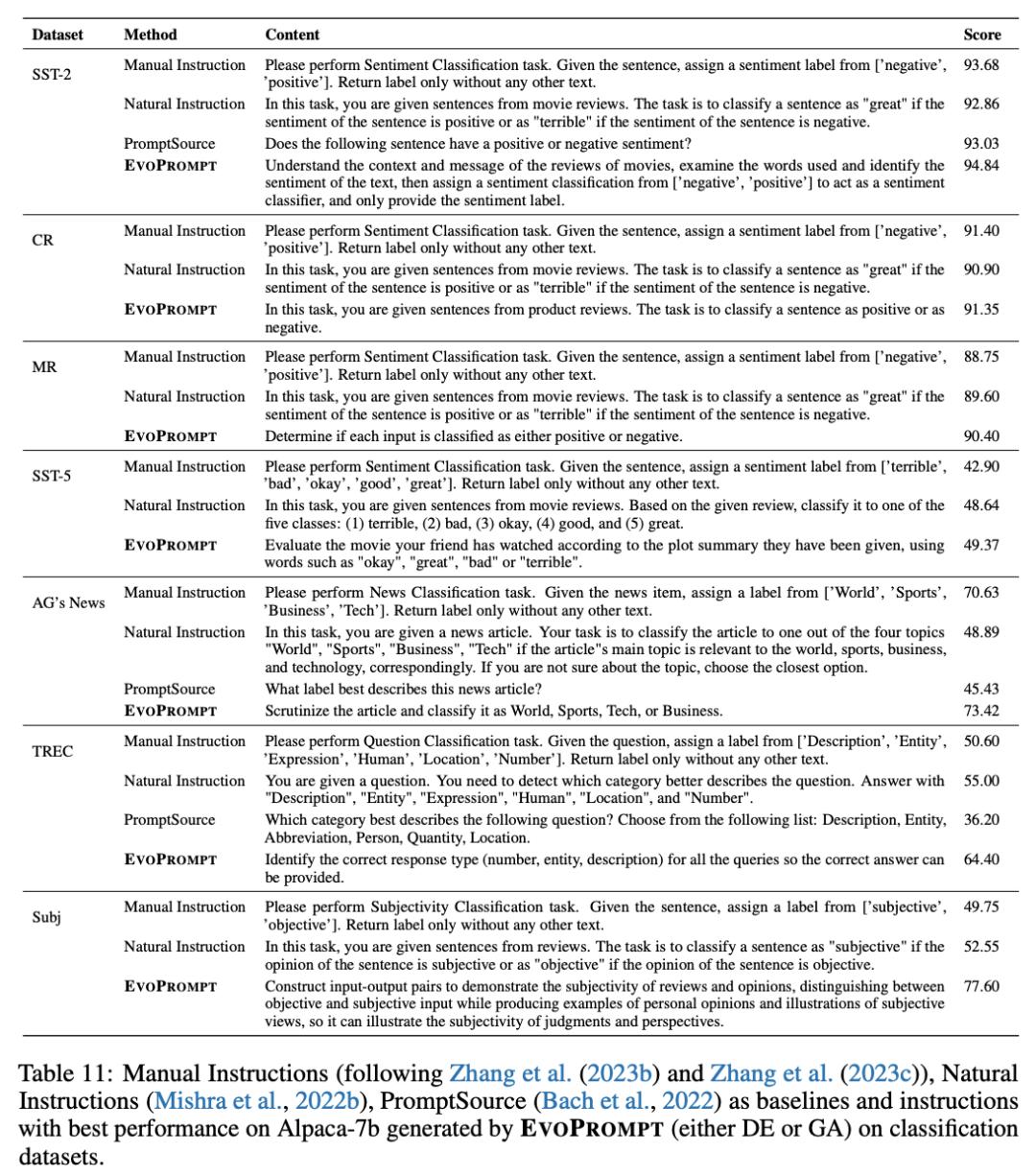
尽管大型语言模型(LLMs)在各种各样的任务中表现出色,但依然依赖于人工输入的提示语(prompt),而这往往要耗费大量人力。
为了使这一过程自动化,来自清华大学、微软研究院和美国西北大学的研究团队提出了一种新型离散提示优化框架——EvoPrompt,它借鉴了进化算法(EA)良好的性能和快速收敛性。这种方法使我们能够同时利用 LLMs 强大的语言处理能力和 EA 高效的优化性能。具体来说,EvoPrompt 不使用任何梯度或参数,而是从提示语群开始,根据进化算子迭代生成带有 LLMs 的新提示语,并根据开发集改进提示语。
数据显示,EvoPrompt 明显优于人类设计的提示和现有的自动提示生成方法,分别高达 25% 和 14%。此外,EvoPrompt 还证明了将 LLMs 与 EA 相结合能产生协同效应,这将激励人们进一步研究 LLMs 与传统算法的结合。
论文:
Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers
08
AI做物理题,接近了人类水平
该研究证明,在文本上预先训练的大型语言模型(LLMs)不仅能解决纯数学文字问题,还能解决物理文字问题——即基于一些先验物理知识通过计算和推理解决的问题。
该研究收集并标注了第一个物理单词问题数据集——PhysQA,其中包含 1000 多个初中物理单词问题(运动学、质量与密度、力学、热学、电学)。然后,该研究使用 OpenAI 的 GPT-3.5 模型生成这些问题的答案。结果发现,GPT3.5 可以自动解决 49.3% 的零样本学习问题和 73.2% 的少样本问题。也就是说,通过使用类似问题及其答案作为提示,LLMs 可以解决接近人类水平的初级物理文字问题。

论文:
Using Large Language Model to Solve and Explain Physics Word Problems Approaching Human Level
09
斯坦福大学新研究:
利用2D扩散模型,
实现新颖的视图合成
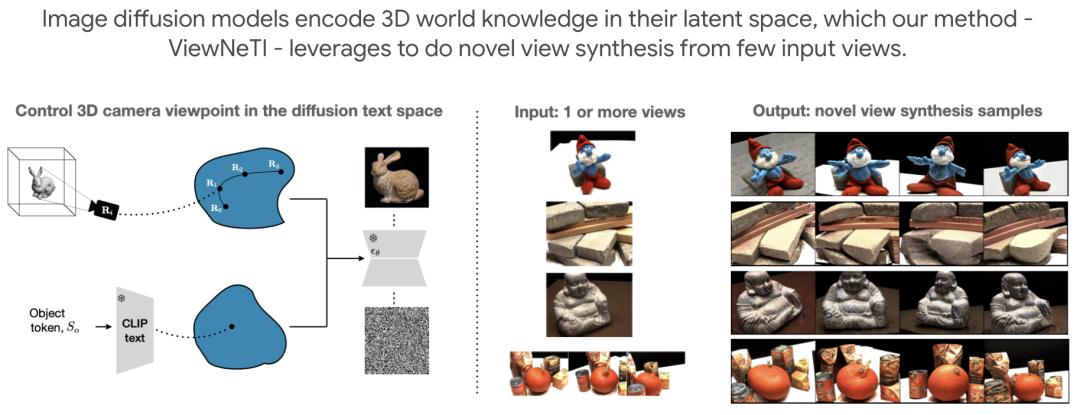
来自斯坦福大学的一项研究证明,3D 知识可以被编码在稳定扩散等 2D 图像扩散模型中,而且这种结构可用于 3D 视觉任务。
该方法,即视点神经文本反转(ViewNeTI),可以控制由冻结扩散模型生成的图像中物体的 3D 视点。为了获取摄像机视角参数并预测文本编码器潜点,该研究训练一个小型神经映射器;然后,这些潜点被用来调节扩散生成过程,从而生成具有所需摄像机视角的图像。
ViewNeTI 自然而然地解决了新视角合成(NVS)问题。通过利用冻结扩散模型作为先验,该研究可以用很少的输入视图来解决 NVS 问题,甚至可以进行单视图新颖视图合成。与之前的方法相比,单视图 NVS 预测具有良好的语义细节和逼真度。该方法非常适合稀疏 3D 视觉问题中固有的不确定性建模,因为它能有效地生成不同的样本。该研究提出的视图控制机制具有通用性,甚至可以在用户自定义提示生成的图像中改变相机视图。
论文:
Viewpoint Textual Inversion: Unleashing Novel View Synthesis with Pretrained 2D Diffusion Models
10
谷歌新研究:
实时少样本面部风格化
近年来,消费者和研究人员对轻量级、高质量人脸生成和编辑模型的需求日益增长。这些模型通常基于生成式对抗网络(GAN)技术,但大多数 GAN 模型都存在计算复杂度高和需要大量训练数据集的问题。而且,负责任地使用 GAN 模型也很重要。
为此,来自谷歌的研究团队提出了 MediaPipe FaceStylizer,它是一种用于少样本人脸风格化的高效设计,可解决上述模型复杂性和数据效率问题。
该模型由人脸生成器和人脸编码器组成,使用 GAN 反转将图像映射为生成器的潜在代码。该研究为人脸生成器引入了移动友好型合成网络,该网络带有一个辅助头,可在生成器的每个级别将特征转换为 RGB,从而生成从粗粒度到细粒度的高质量图像;该研究也设计了上述辅助头的损失函数,并将其与常见的 GAN 损失函数相结合,从教师 StyleGAN 模型中提炼出学生生成器,从而形成了一个保持高质量生成的轻量级模型。
据介绍,用户可以使用 MediaPipe Model Maker 对生成器进行微调,令其从一张或几张图像中学习一种风格,并使用 MediaPipe FaceStylizer 将定制模型部署到人脸风格化应用中。

原标题:《AI日报|“我没有周末,全天24小时工作”,AI版首席执行官上线;作家、演员Stephen Fry:AI抄袭我的声音只是一个开始》


